
인공 신경망의 동작에 대한 전체적인 개요를 알기 위해서는 ‘머신러닝 스타일 : 인공 신경망과 작동 원리, 함수 구조’라는 기사를 살펴보자. 참고로 이번 기사에서 제시하는 예제는 프로덕션급 시스템을 염두에 둔 것이 아니며, 이해하기 쉽게 설계된 데모의 모든 주요 구성요소를 보여주기 위한 용도로 작성됐다.
기본적인 신경망
신경망은 뉴런(neuron)이라는 노드로 구성된 그래프다. 뉴런은 계산의 기본 단위로, 입력을 받아서 입력별 가중치, 노드별 편향, 최종 함수 처리기(활성화 함수라고 함) 알고리즘을 사용해 입력을 처리한다. 다음 그림 1은 입력 값이 2가지인 뉴런을 보여준다. 이 모델은 변이도가 넓지만 기사 데모에서는 이 구성을 그대로 사용한다.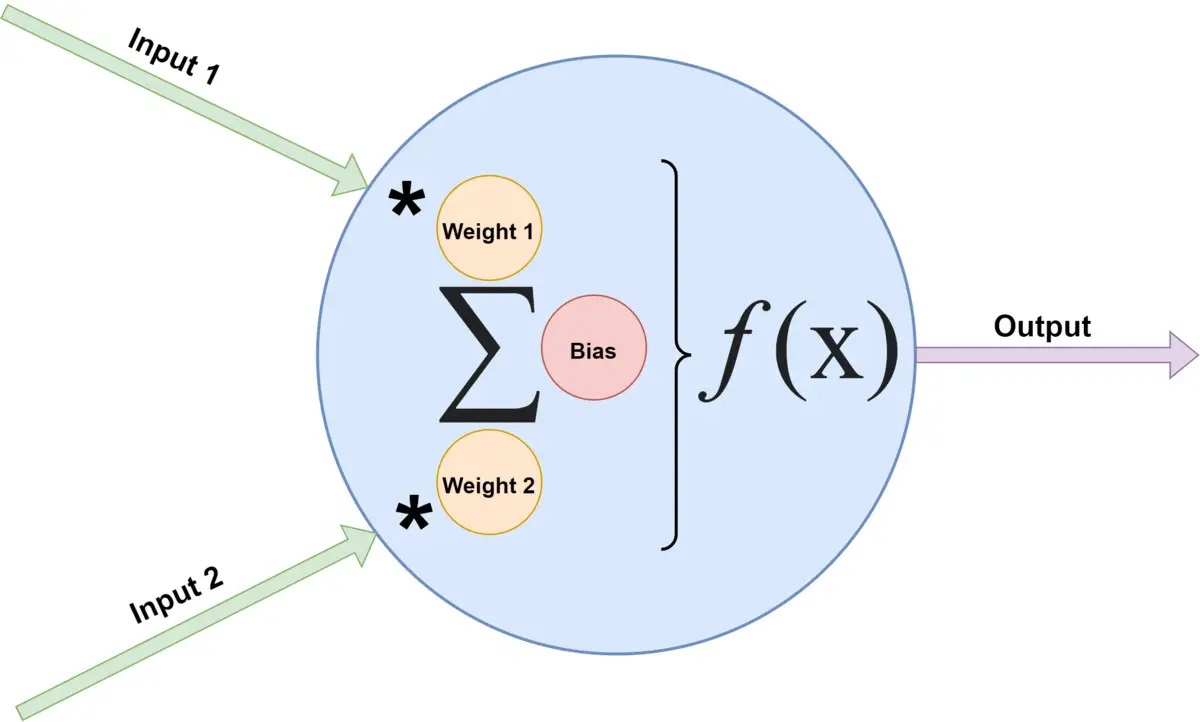
첫 단계는 이러한 값을 저장할 뉴런(Neuron) 클래스를 모델링하는 것이다. 예시 1에서 Neuron 클래스를 볼 수 있다. 참고로 이 부분은 클래스의 첫 버전이고 기능을 추가함에 따라 클래스도 바뀐다.
class Neuron {
Random random = new Random();
private Double bias = random.nextDouble(-1, 1);
public Double weight1 = random.nextDouble(-1, 1);
private Double weight2 = random.nextDouble(-1, 1);
public double compute(double input1, double input2){
double preActivation = (this.weight1 * input1) + (this.weight2 * input2) + this.bias;
double output = Util.sigmoid(preActivation);
return output;
}
}
예시 1. 간단한 뉴런(Neuron) 클래스
Neuron은 bias, weight1, weight2의 3개 멤버가 있는 간단한 클래스다. 각 멤버는 -1에서 1 사이의 무작위 실수로 초기화된다.
뉴런의 출력을 계산할 때는 그림 1의 알고리즘에 따라 각 입력에 가중치를 곱하고 편향을 더한다(input1 * weight1 + input2 * weight2 + bias). 이렇게 해서 나온 처리되지 않은 계산(preActivation)을 활성화 함수에 집어넣는다. 여기서는 값을 -1 ~ 1 범위로 압축하는 시그모이드(Sigmoid) 활성화 함수를 사용한다. 예시 2는 Util.sigmoid() 정적 메서드를 보여준다.
public class Util {
public static double sigmoid(double in){
return 1 / (1 + Math.exp(-in));
}
}
예시 2. 시그모이드 활성화 함수
뉴런이 어떻게 작동하는지 알아봤으니, 이제 뉴런을 네트워크에 넣어 보자. 예시 3에서 볼 수 있듯이 뉴런 목록이 있는 네트워크(Network) 클래스를 사용한다.
class Network {
List<Neuron> neurons = Arrays.asList(
new Neuron(), new Neuron(), new Neuron(), /* input nodes */
new Neuron(), new Neuron(), /* hidden nodes */
new Neuron()); /* output node */
}
}
예시 3. 신경망 클래스
뉴런 목록은 1차원이지만 사용 중에 뉴런을 연결해서 네트워크를 형성하도록 할 것이다. 처음 3개의 뉴런은 입력, 두 번째와 세 번째는 숨은 입력, 마지막이 출력 노드다.
예측 수행
이제 네트워크를 사용해서 예측을 해보자. 두 개의 입력 정수와 0~1의 응답 형식이 있는 간단한 데이터 집합을 사용한다. 필자의 예제는 체중-신장 조합을 사용해서 체중이 높고 신장이 클수록 그 사람이 남자일 가능성이 높아진다는 전제를 기반으로 성별을 추정한다. 모든 2가지 요소, 단일 출력 확률에 사용할 수 있는 공식이다. 입력을 벡터라고 보면 전체 뉴런 함수는 벡터를 스칼라 값으로 변환한다고 볼 수 있다. 네트워크의 예측 단계는 예시 4와 같다.public Double predict(Integer input1, Integer input2){
return neurons.get(5).compute(
neurons.get(4).compute(
neurons.get(2).compute(input1, input2),
neurons.get(1).compute(input1, input2)
),
neurons.get(3).compute(
neurons.get(1).compute(input1, input2),
neurons.get(0).compute(input1, input2)
)
);
}
예시 4. 네트워크 예측
예시 4를 보면 2개의 입력이 처음 3개의 뉴런으로 들어가고, 출력이 뉴런 4와 5로 전달되고, 이게 다시 출력 뉴런으로 전달된다. 이런 프로세스를 순전파(feedforward)라고 한다. 이제 예시 5와 같이 네트워크에 예측을 요청할 수 있다.
Network network = new Network();
Double prediction = network.predict(Arrays.asList(115, 66));
System.out.println(“prediction: “ + prediction);
예시 5. 예측 수행하기
뭔가 나오긴 하지만 이는 임의의 체중과 편향의 결과다. 실질적인 예측을 위해서는 먼저 네트워크를 학습시켜야 한다.
네트워크 학습시키기
신경망 학습은 역전파(backpropagation)라는 프로세스에 따른다(역전파에 대해서는 다음 기사에서 더 자세히 소개할 예정). 역전파는 기본적으로 네트워크의 역방향으로 변경을 푸시해서 원하는 목표를 향해 출력이 이동하도록 하는 것이다.역전파는 함수 미분을 사용해 수행할 수 있지만 예제에서는 조금 다른 방식을 사용해서 모든 뉴런에 ‘변이’ 기능을 부여한다. 각 학습 라운드(에포크(epoch)라고 함)에서 다른 뉴런을 선택해 그 속성(weight1, weight2, bias) 중 하나를 무작위로 소폭 조정한 다음 결과가 개선되는지 여부를 확인한다. 결과가 개선되면 remember() 메서드로 변경을 유지하고, 결과가 악화되면 forget() 메서드로 변경을 버린다.
클래스 멤버(가중치와 편향의 old* 버전)를 추가해서 변경을 추적한다. 예시 6에서 mutate(), remember(), forget() 메서드를 볼 수 있다.
public class Neuron() {
private Double oldBias = random.nextDouble(-1, 1), bias = random.nextDouble(-1, 1);
public Double oldWeight1 = random.nextDouble(-1, 1), weight1 = random.nextDouble(-1, 1);
private Double oldWeight2 = random.nextDouble(-1, 1), weight2 = random.nextDouble(-1, 1);
public void mutate(){
int propertyToChange = random.nextInt(0, 3);
Double changeFactor = random.nextDouble(-1, 1);
if (propertyToChange == 0){
this.bias += changeFactor;
} else if (propertyToChange == 1){
this.weight1 += changeFactor;
} else {
this.weight2 += changeFactor;
};
}
public void forget(){
bias = oldBias;
weight1 = oldWeight1;
weight2 = oldWeight2;
}
public void remember(){
oldBias = bias;
oldWeight1 = weight1;
oldWeight2 = weight2;
}
}
예시 6. mutate(), remember(), forget()
간단하다. mutate() 메서드가 무작위로 속성 하나와 -1에서 1 사이의 값을 선택한 다음 속성을 변경한다. forget() 메서드는 변경을 이전 값으로 되돌리고 remember() 메서드는 새 값을 버퍼로 복사한다. 이제 Neuron의 새로운 기능을 사용하기 위해 예시 7과 같이 Network에 train() 메서드를 추가한다.
public void train(List<List<Integer>> data, List<Double> answers){
Double bestEpochLoss = null;
for (int epoch = 0; epoch < 1000; epoch++){
// adapt neuron
Neuron epochNeuron = neurons.get(epoch % 6);
epochNeuron.mutate(this.learnFactor);
List<Double> predictions = new ArrayList<Double>();
for (int i = 0; i < data.size(); i++){
predictions.add(i, this.predict(data.get(i).get(0), data.get(i).get(1)));
}
Double thisEpochLoss = Util.meanSquareLoss(answers, predictions);
if (bestEpochLoss == null){
bestEpochLoss = thisEpochLoss;
epochNeuron.remember();
} else {
if (thisEpochLoss < bestEpochLoss){
bestEpochLoss = thisEpochLoss;
epochNeuron.remember();
} else {
epochNeuron.forget();
}
}
}
예시 7. Network.train() 메서드
train() 메서드는 인수의 data 및 answers List에 대해 1,000번 반복된다. 같은 크기의 학습 집합이며 data에는 입력 값이, answers에는 알려진 정답이 저장된다. 메서드는 이 학습 집합에 대해 반복 실행되면서 알려진 올바른 대답과 비교해 네트워크가 얼마나 잘 추정했는지에 대한 값을 구한다. 그런 다음 임의의 뉴런을 변이시키고, 새 테스트가 더 나은 예측이었음이 확인되면 변경을 유지한다.
결과 확인
신경망에서 결과 집합을 테스트하기 위한 일반적인 방법인 평균 제곱 오차(MSE) 공식을 사용해서 결과를 확인할 수 있다. 예시 8에서 MSE 함수를 볼 수 있다.public static Double meanSquareLoss(List<Double> correctAnswers, List<Double> predictedAnswers){
double sumSquare = 0;
for (int i = 0; i < correctAnswers.size(); i++){
double error = correctAnswers.get(i) - predictedAnswers.get(i);
sumSquare += (error * error);
}
return sumSquare / (correctAnswers.size());
}
예시 8. MSE 함수
시스템 미세 조정
이제 남은 것은 학습 데이터를 네트워크에 넣어 더 많은 예측을 시험하는 것이다. 예시 9에서 학습 데이터를 제공하는 방법을 볼 수 있다.List<List<Integer>> data = new ArrayList<List<Integer>>();
data.add(Arrays.asList(115, 66));
data.add(Arrays.asList(175, 78));
data.add(Arrays.asList(205, 72));
data.add(Arrays.asList(120, 67));
List<Double> answers = Arrays.asList(1.0,0.0,0.0,1.0);
Network network = new Network();
network.train(data, answers);
예시 9. 학습 데이터
예시 9에서 학습 데이터는 2차원 정수 집합 목록(체중과 신장이라고 생각하면 됨)과 대답 목록(1.0이 여성, 0.0이 남성)이다. 학습 알고리즘에 로깅을 추가하면 실행 시 예시 10과 비슷한 출력을 얻게 된다.
// Logging:
if (epoch % 10 == 0) System.out.println(String.format("Epoch: %s | bestEpochLoss: %.15f | thisEpochLoss: %.15f", epoch, bestEpochLoss, thisEpochLoss));
// output:
Epoch: 910 | bestEpochLoss: 0.034404863820424 | thisEpochLoss: 0.034437939546120
Epoch: 920 | bestEpochLoss: 0.033875954196897 | thisEpochLoss: 0.431451026477016
Epoch: 930 | bestEpochLoss: 0.032509260025490 | thisEpochLoss: 0.032509260025490
Epoch: 940 | bestEpochLoss: 0.003092720117159 | thisEpochLoss: 0.003098025397281
Epoch: 950 | bestEpochLoss: 0.002990128276146 | thisEpochLoss: 0.431062364628853
Epoch: 960 | bestEpochLoss: 0.001651762688346 | thisEpochLoss: 0.001651762688346
Epoch: 970 | bestEpochLoss: 0.001637709485751 | thisEpochLoss: 0.001636810460399
Epoch: 980 | bestEpochLoss: 0.001083365453009 | thisEpochLoss: 0.391527869500699
Epoch: 990 | bestEpochLoss: 0.001078338540452 | thisEpochLoss: 0.001078338540452/
예시 10. 트레이너 로깅
예시 10은 서서히 하강하는 손실(우측으로부터의 오차 괴리)을 보여준다. 즉, 정확한 예측에 가까워지고 있다. 이제 예시 11과 같이 실제 데이터를 사용해서 모델이 얼마나 잘 작동하는지 확인하기만 하면 된다.
System.out.println("");
System.out.println(String.format(" male, 167, 73: %.10f", network.predict(167, 73)));
System.out.println(String.format("female, 105, 67: %.10", network.predict(105, 67)));
System.out.println(String.format("female, 120, 72: %.10f | network1000: %.10f", network.predict(120, 72)));
System.out.println(String.format(" male, 143, 67: %.10f | network1000: %.10f", network.predict(143, 67)));
System.out.println(String.format(" male', 130, 66: %.10f | network: %.10f", network.predict(130, 66)));
예시 11. 예측
예시 11에서는 학습된 네트워크를 가져와 데이터를 집어넣고 예측을 출력한다. 결과는 예시 12와 같다.
male, 167, 73: 0.0279697143
female, 105, 67: 0.9075809407
female, 120, 72: 0.9075808235
male, 143, 67: 0.0305401413
male, 130, 66: network: 0.9009811922
예시 12. 학습된 예측
예시 12를 보면 대부분의 값 쌍(벡터)에서 네트워크가 꽤 좋은 결과를 도출했음을 알 수 있다. 여성 데이터 집합에 대해 1에 상당히 근접한 약 .907의 추정치를 제공한다. 두 남성 수치는 .027과 .030으로 0에 가깝다. 이상치인 남성 데이터 집합(130, 67)은 여성으로 볼 수 있지만, 확신도는 상대적으로 낮은 .900이다.
이 시스템의 세부 사항을 조정하는 방법은 여러가지다. 예를 들어 학습 실행에서 에포크의 수가 있다. 에포크가 많을수록 모델은 데이터에 맞게 더 조정된다. 더 많은 에포크를 실행하면 학습 집합에 부합하는 라이브 데이터의 정확도를 개선할 수 있지만 과도 학습으로 이어질 수도 있다. 과도 학습 모델은 엣지 케이스에 대해 높은 확신도로 틀린 결과를 예측하는 모델이다.
editor@itworld.co.kr
함께 보면 좋은 콘텐츠




Sponsored
Surfshark
“유료 VPN, 분명한 가치 있다” VPN 선택 가이드
ⓒ Surfshark VPN(가상 사설 네트워크, Virtual Private Network)은 인터넷 사용자에게 개인 정보 보호와 보안을 제공하는 중요한 도구로 널리 인정받고 있다. VPN은 공공 와이파이 환경에서도 데이터를 안전하게 전송할 수 있고, 개인 정보를 보호하는 데 도움을 준다. VPN 서비스의 수요가 증가하는 것도 같은 이유에서다. 동시에 유료와 무료 중 어떤 VPN을 선택해야 할지 많은 관심을 가지고 살펴보는 사용자가 많다. 가장 먼저 사용자의 관심을 끄는 것은 별도의 예산 부담이 없는 무료 VPN이지만, 그만큼의 한계도 있다. 무료 VPN, 정말 괜찮을까? 무료 VPN 서비스는 편리하고 경제적 부담도 없지만 고려할 점이 아예 없는 것은 아니다. 보안 우려 대부분의 무료 VPN 서비스는 유료 서비스에 비해 보안 수준이 낮을 수 있다. 일부 무료 VPN은 사용자 데이터를 수집해 광고주나 서드파티 업체에 판매하는 경우도 있다. 이러한 상황에서 개인 정보가 유출될 우려가 있다. 속도와 대역폭 제한 무료 VPN 서비스는 종종 속도와 대역폭에 제한을 생긴다. 따라서 사용자는 느린 인터넷 속도를 경험할 수 있으며, 높은 대역폭이 필요한 작업을 수행하는 데 제약을 받을 수 있다. 서비스 제한 무료 VPN 서비스는 종종 서버 위치가 적거나 특정 서비스 또는 웹사이트에 액세스하지 못하는 경우가 생긴다. 또한 사용자 수가 늘어나 서버 부하가 증가하면 서비스의 안정성이 저하될 수 있다. 광고 및 추적 위험 일부 무료 VPN은 광고를 삽입하거나 사용자의 온라인 활동을 추적하여 광고주에게 판매할 수 있다. 이 경우 사용자가 광고를 보아야 하거나 개인 정보를 노출해야 할 수도 있다. 제한된 기능 무료 VPN은 유료 버전에 비해 기능이 제한될 수 있다. 예를 들어, 특정 프로토콜이나 고급 보안 기능을 지원하지 않는 경우가 그렇다. 유료 VPN의 필요성 최근 유행하는 로맨스 스캠은 인터넷 사기의 일종으로, 온라인 데이트나 소셜 미디어를 통해 가짜 프로필을 만들어 상대를 속이는 행위다. 이러한 상황에서 VPN은 사용자가 안전한 연결을 유지하고 사기 행위를 방지하는 데 도움이 된다. VPN을 통해 사용자는 상대방의 신원을 확인하고 의심스러운 활동을 감지할 수 있다. 서프샤크 VPN은 구독 요금제 가입 후 7일간의 무료 체험을 제공하고 있다. ⓒ Surfshark 그 외에도 유료 VPN만의 강점을 적극 이용해야 하는 이유는 다음 3가지로 요약할 수 있다. 보안 강화 해외 여행객이 증가함에 따라 공공 와이파이를 사용하는 경우가 늘어나고 있다. 그러나 공공 와이파이는 보안이 취약해 개인 정보를 노출할 위험이 있다. 따라서 VPN을 사용하여 데이터를 암호화하고 개인 정보를 보호하는 것이 중요하다. 서프샤크 VPN은 사용자의 개인 정보를 안전하게 유지하고 해킹을 방지하는 데 유용하다. 개인정보 보호 인터넷 사용자의 검색 기록과 콘텐츠 소비 패턴은 플랫폼에 의해 추적될 수 있다. VPN을 사용하면 사용자의 IP 주소와 로그를 숨길 수 있으며, 개인 정보를 보호할 수 있다. 또한 VPN은 사용자의 위치를 숨기고 인터넷 활동을 익명으로 유지하는 데 도움이 된다. 지역 제한 해제 해외 여행 중에도 한국에서 송금이 필요한 경우가 생길 수 있다. 그러나 IP가 해외 주소이므로 은행 앱에 접근하는 것이 제한될 수 있다. VPN을 사용하면 지역 제한을 해제해 해외에서도 한국 인터넷 서비스를 이용할 수 있다. 따라서 해외에서도 안전하고 편리하게 인터넷을 이용할 수 있다. 빠르고 안전한 유료 VPN, 서프샤크 VPN ⓒ Surfshark 뛰어난 보안 서프샤크 VPN은 강력한 암호화 기술을 사용하여 사용자의 인터넷 연결을 안전하게 보호한다. 이는 사용자의 개인 정보와 데이터를 보호하고 외부 공격으로부터 사용자를 보호하는 데 도움이 된다. 다양한 서버 위치 서프샤크 VPN은 전 세계 곳곳에 여러 서버가 위치하고 있어, 사용자가 지역 제한된 콘텐츠에 액세스할 수 있다. 해외에서도 로컬 콘텐츠에 손쉽게 접근할 수 있음은 물론이다. 속도와 대역폭 서프샤크 VPN은 빠른 속도와 무제한 대역폭을 제공하여 사용자가 원활한 인터넷 경험을 누릴 수 있도록 지원한다. 온라인 게임, 스트리밍, 다운로드 등 대역폭이 필요한 활동에 이상적이다. 다양한 플랫폼 지원 서프샤크 VPN은 다양한 플랫폼 및 디바이스에서 사용할 수 있다. 윈도우, 맥OS, iOS, 안드로이드 등 다양한 운영체제 및 디바이스에서 호환되어 사용자가 어디서나 안전한 인터넷을 즐길 수 있다. 디바이스 무제한 연결 서프샤크 VPN은 무제한 연결을 제공하여 사용자가 필요할 때 언제든지 디바이스의 갯수에 상관없이 VPN을 사용할 수 있다.



