
예측은 예측 분석, 예지 정비, 제품 계획, 예산 편성 등 모든 종류의 현업 업무에서 중요한 작업이다. 많은 예측 문제에는 시계열 데이터가 사용되는데, 이 때문에 XG부스트는 오픈소스 시계열 데이터베이스인 인플럭스DB(InfluxDB)와 함께 사용하는 것이 일반적이다.
여기서는 XG부스트용 파이썬 패키지를 사용해 인플럭스DB 시계열 데이터베이스의 데이터를 예측하는 방법을 살펴본다. 또한 인플럭스DB 파이썬 클라이언트 라이브러리를 사용해 인플럭스DB의 데이터를 쿼리하고, 시계열 데이터를 다루기 쉽게 하기 위해 이 데이터를 판다스 데이터프레임(Pandas DataFrame)으로 변환한다. 그런 다음 예측을 수행한다. XG부스트의 이점에 대해서도 세부적으로 알아본다.
요구사항
여기서는 홈브루(Homebrew)를 통해 파이썬 3을 설치한 맥OS 시스템에서 실행했다. 파이썬 및 클라이언트 설치를 간소화하기 위해 virtualenv, pyenv, conda-env와 같은 부가적인 툴도 설치할 것을 권한다. 그 외의 전체 요구사항은 다음과 같다.- influxdb-client = 1.30.0
- pandas = 1.4.3
- xgboost >= 1.7.3
- influxdb-client >= 1.30.0
- pandas >= 1.4.3
- matplotlib >= 3.5.2
- sklearn >= 1.1.1
또한 여기서는 무료 티어 인플럭스DB 클라우드 계정이 있고 버킷과 토큰을 만들었음을 전제한다. 버킷은 데이터베이스, 또는 인플럭스DB 내의 데이터 조직에서 가장 높은 계층이라고 생각하면 된다. 여기서는 NOAA라는 이름의 버킷을 만든다.
결정 트리, 랜덤 포레스트, 그라디언트 부스팅
XG부스트가 무엇인지 이해하려면 결정 트리(decision trees), 랜덤 포레스트(random forests), 그라디언트 부스팅(gradient boosting)을 이해해야 한다. 결정 트리는 특징에 대한 일련의 테스트로 구성된 지도 학습 방법의 한 유형이다. 각 노드는 테스트이며 모든 노드가 플로우차트 구조로 구성된다. 가지는 어떤 리프 또는 클래스 레이블이 입력 데이터에 할당될 것인지 최종적으로 결정하는 조건을 나타낸다.
결정 트리, 랜덤 포레스트, 그라디언트 부스팅의 기본 원칙은 “약한 학습기” 또는 분류기 그룹이 집합적으로 강한 예측을 수행한다는 것이다. 랜덤 포레스트에는 여러 결정 트리가 포함된다. 결정 트리의 각 노드가 약한 학습기로 간주되는 경우 포레스트의 각 결정 트리는 랜덤 포레스트 모델에서 다수의 약한 학습기 중 하나로 간주된다. 일반적으로 모든 데이터는 무작위로 하위 집합으로 분할되어 다양한 결정 트리를 통해 전달된다.
결정 트리와 랜섬 포레스트를 사용하는 그라디언트 부스팅은 이와 비슷하지만 구조화되는 방식에 차이가 있다. 그라디언트 부스트 트리에도 결정 트리 포레스트가 포함되지만 이러한 트리는 덧붙이는 식으로 구축되며 모든 데이터가 결정 트리 모음을 통과해 전달된다(이 부분에 대해서는 다음 섹션에서 더 설명함). 그라디언트 부스트 트리에는 분류 또는 회귀 트리 집합이 포함될 수 있다. 분류 트리는 고양이 또는 개 등 개별 값에 사용되고 회귀 트리는 0에서 100까지 등 연속된 값에 사용된다.
XG부스트란
그라디언트 부스팅은 분류 및 예측에 사용되는 머신러닝 알고리즘이다. XG부스트는 그라디언트 부스팅의 극단적인 유형이다. 병렬 처리를 통해 더 효율적으로 그라디언트 부스팅을 수행한다. XG부스트 문서에서 발췌한 다음 다이어그램은 그라디언트 부스팅을 사용해 개인이 비디오 게임을 좋아할지를 예측하는 방법을 보여준다.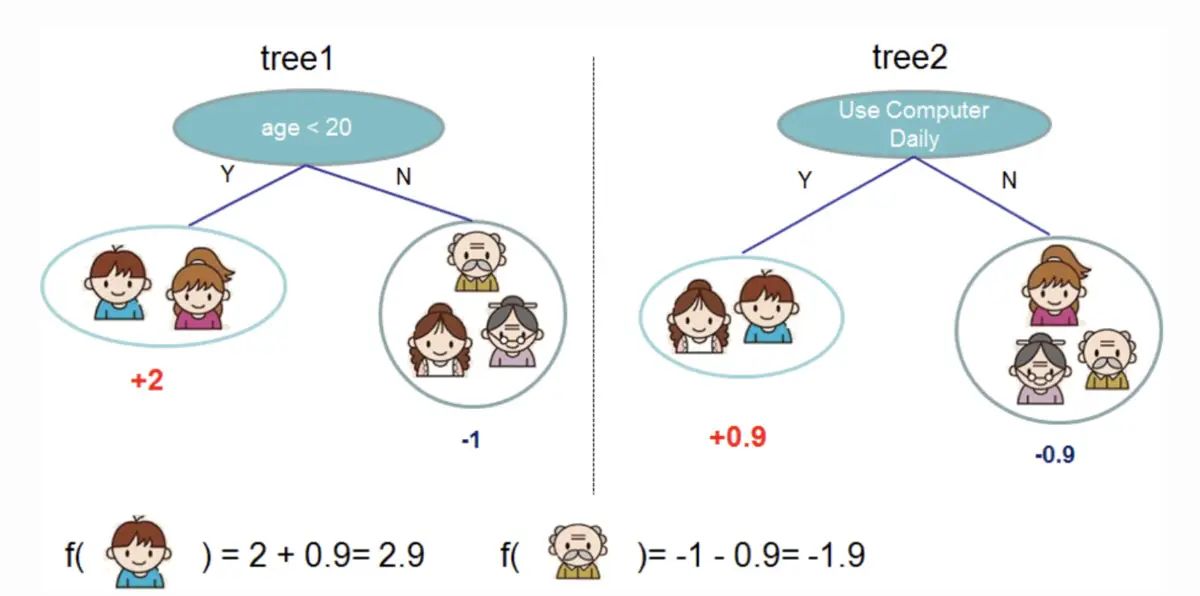
XG부스트 문서의 부스트 트리 소개를 참고하면 그라디언트 부스트 트리와 XG부스트의 동작에 대해 더 자세히 알아볼 수 있다.
XG부스트의 장점은 다음과 같다.
- 이해하기가 비교적 쉽다.
- 특징이 거의 없는 소량의 구조적인 일반 데이터에서 잘 작동한다.
XG부스트의 단점은 다음과 같다.
- 과적합이 잘 발생하고 이상치에 민감하다. XG부스트를 사용한 예측에는 시계열 데이터의 구체화된 뷰를 사용하는 것이 좋다.
- 희소 및 비지도 데이터에 대해서는 효과가 떨어진다.
XG부스트를 사용한 시계열 예측
여기서는 인플럭스DB와 함께 제공되는 공기 센서 샘플 데이터를 사용한다. 이 데이터 집합에는 여러 센서에서 가져온 온도 데이터가 포함된다. 한 센서의 온도 예측을 생성해 보자. 데이터의 모습은 다음과 같다.
다음 플럭스(Flux) 코드를 사용해 데이터 집합을 가져오고 하나의 시계열로 필터링한다(플럭스는 인플럭스DB의 쿼리 언어).
import "influxdata/influxdb/sample"
//dataset is regular time series at 10 second intervals
data = sample.data(set: "airSensor")
|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")
랜섬 포레스트와 그라디언트 부스팅을 시계열 예측에 사용할 수 있지만 이를 위해서는 지도 학습용으로 데이터를 변환해야 한다. 즉, 슬라이딩 윈도우 방식이나 지연 방법으로 데이터를 앞으로 이동해서 시계열 데이터를 지도 학습 집합으로 변환해야 한다. 플럭스로도 데이터를 준비할 수 있다. 이상적으로는 먼저 몇 가지 자기상관(autocorrelation) 분석을 수행해 사용할 최적의 지연을 결정해야 한다. 여기서는 간단히 하기 위해 다음 플럭스 코드를 사용해 데이터를 하나의 일정한 시간 간격만큼 이동한다.
import "influxdata/influxdb/sample"
data = sample.data(set: "airSensor")
|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")
shiftedData = data
|> timeShift(duration: 10s , columns: ["_time"] )
join.time(left: data, right: shiftedData, as: (l, r) => ({l with data: l._value, shiftedData: r._value}))
|> drop(columns: ["_measurement", "_time", "_value", "sensor_id", "_field"])

모델 입력에 부가적인 지연된 데이터를 추가하려면 다음 플럭스 논리를 대신 사용하면 된다.
import "influxdata/influxdb/sample"
data = sample.data(set: "airSensor")
|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")
shiftedData1 = data
|> timeShift(duration: 10s , columns: ["_time"] )
|> set(key: "shift" , value: "1" )
shiftedData2 = data
|> timeShift(duration: 20s , columns: ["_time"] )
|> set(key: "shift" , value: "2" )
shiftedData3 = data
|> timeShift(duration: 30s , columns: ["_time"] )
|> set(key: "shift" , value: "3")
shiftedData4 = data
|> timeShift(duration: 40s , columns: ["_time"] )
|> set(key: "shift" , value: "4")
union(tables: [shiftedData1, shiftedData2, shiftedData3, shiftedData4])
|> pivot(rowKey:["_time"], columnKey: ["shift"], valueColumn: "_value")
|> drop(columns: ["_measurement", "_time", "_value", "sensor_id", "_field"])
// remove the NaN values
|> limit(n:360)
|> tail(n: 356)
또한 워크 포워드(walk-forward) 유효성 검사를 사용해 알고리즘을 훈련시켜야 한다. 이를 위해서는 데이터 집합을 테스트 집합과 훈련 집합으로 분할한다. 그런 다음 XGBRegressor를 사용해 XG부스트 모델을 훈련시키고 적합 방법으로 예측을 수행한다. 마지막으로 MAE(절대 오차 평균)를 사용해서 예측의 정확도를 확인한다. 10초 지연에서 MAE는 0.035로 계산된다. 해석하면 예측의 96.5%가 아주 좋다는 의미다. 다음 그래프는 훈련/테스트 분할의 예상된 값에 대비해 XG부스트에서 예측된 결과를 보여준다.

다음은 전체 스크립트다. 이 코드의 대부분은 이 자습서에서 차용했다.
from numpy import asarray
from sklearn.metrics import mean_absolute_error
from xgboost import XGBRegressor
from matplotlib import pyplot
from influxdb_client import InfluxDBClient
from influxdb_client.client.write_api import SYNCHRONOUS
# query data with the Python InfluxDB Client Library and transform data into a supervised learning problem with Flux
client = InfluxDBClient(url="https://us-west-2-1.aws.cloud2.influxdata.com", token="NyP-HzFGkObUBI4Wwg6Rbd-_SdrTMtZzbFK921VkMQWp3bv_e9BhpBi6fCBr_0-6i0ev32_XWZcmkDPsearTWA==", org="0437f6d51b579000")
# write_api = client.write_api(write_options=SYNCHRONOUS)
query_api = client.query_api()
df = query_api.query_data_frame('import "join"'
'import "influxdata/influxdb/sample"'
'data = sample.data(set: "airSensor")'
'|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")'
'shiftedData = data'
'|> timeShift(duration: 10s , columns: ["_time"] )'
'join.time(left: data, right: shiftedData, as: (l, r) => ({l with data: l._value, shiftedData: r._value}))'
'|> drop(columns: ["_measurement", "_time", "_value", "sensor_id", "_field"])'
'|> yield(name: "converted to supervised learning dataset")'
)
df = df.drop(columns=['table', 'result'])
data = df.to_numpy()
# split a univariate dataset into train/test sets
def train_test_split(data, n_test):
return data[:-n_test:], data[-n_test:]
# fit an xgboost model and make a one step prediction
def xgboost_forecast(train, testX):
# transform list into array
train = asarray(train)
# split into input and output columns
trainX, trainy = train[:, :-1], train[:, -1]
# fit model
model = XGBRegressor(objective='reg:squarederror', n_estimators=1000)
model.fit(trainX, trainy)
# make a one-step prediction
yhat = model.predict(asarray([testX]))
return yhat[0]
# walk-forward validation for univariate data
def walk_forward_validation(data, n_test):
predictions = list()
# split dataset
train, test = train_test_split(data, n_test)
history = [x for x in train]
# step over each time-step in the test set
for i in range(len(test)):
# split test row into input and output columns
testX, testy = test[i, :-1], test[i, -1]
# fit model on history and make a prediction
yhat = xgboost_forecast(history, testX)
# store forecast in list of predictions
predictions.append(yhat)
# add actual observation to history for the next loop
history.append(test[i])
# summarize progress
print('>expected=%.1f, predicted=%.1f' % (testy, yhat))
# estimate prediction error
error = mean_absolute_error(test[:, -1], predictions)
return error, test[:, -1], predictions
# evaluate
mae, y, yhat = walk_forward_validation(data, 100)
print('MAE: %.3f' % mae)
# plot expected vs predicted
pyplot.plot(y, label='Expected')
pyplot.plot(yhat, label='Predicted')
pyplot.legend()
pyplot.show()
결론
이 글이 XG부스트와 인플럭스DB를 활용해 예측을 수행하는 방법에 관해 관심을 갖는 계기가 되기를 기대한다. 이 리포지토리를 방문하면 여기서 설명한 많은 알고리즘과 인플럭스DB를 사용해서 예측과 이상 탐지를 수행하는 방법에 관한 예제를 볼 수 있다.
editor@itworld.co.kr
Sponsored
Surfshark
“유료 VPN, 분명한 가치 있다” VPN 선택 가이드
ⓒ Surfshark VPN(가상 사설 네트워크, Virtual Private Network)은 인터넷 사용자에게 개인 정보 보호와 보안을 제공하는 중요한 도구로 널리 인정받고 있다. VPN은 공공 와이파이 환경에서도 데이터를 안전하게 전송할 수 있고, 개인 정보를 보호하는 데 도움을 준다. VPN 서비스의 수요가 증가하는 것도 같은 이유에서다. 동시에 유료와 무료 중 어떤 VPN을 선택해야 할지 많은 관심을 가지고 살펴보는 사용자가 많다. 가장 먼저 사용자의 관심을 끄는 것은 별도의 예산 부담이 없는 무료 VPN이지만, 그만큼의 한계도 있다. 무료 VPN, 정말 괜찮을까? 무료 VPN 서비스는 편리하고 경제적 부담도 없지만 고려할 점이 아예 없는 것은 아니다. 보안 우려 대부분의 무료 VPN 서비스는 유료 서비스에 비해 보안 수준이 낮을 수 있다. 일부 무료 VPN은 사용자 데이터를 수집해 광고주나 서드파티 업체에 판매하는 경우도 있다. 이러한 상황에서 개인 정보가 유출될 우려가 있다. 속도와 대역폭 제한 무료 VPN 서비스는 종종 속도와 대역폭에 제한을 생긴다. 따라서 사용자는 느린 인터넷 속도를 경험할 수 있으며, 높은 대역폭이 필요한 작업을 수행하는 데 제약을 받을 수 있다. 서비스 제한 무료 VPN 서비스는 종종 서버 위치가 적거나 특정 서비스 또는 웹사이트에 액세스하지 못하는 경우가 생긴다. 또한 사용자 수가 늘어나 서버 부하가 증가하면 서비스의 안정성이 저하될 수 있다. 광고 및 추적 위험 일부 무료 VPN은 광고를 삽입하거나 사용자의 온라인 활동을 추적하여 광고주에게 판매할 수 있다. 이 경우 사용자가 광고를 보아야 하거나 개인 정보를 노출해야 할 수도 있다. 제한된 기능 무료 VPN은 유료 버전에 비해 기능이 제한될 수 있다. 예를 들어, 특정 프로토콜이나 고급 보안 기능을 지원하지 않는 경우가 그렇다. 유료 VPN의 필요성 최근 유행하는 로맨스 스캠은 인터넷 사기의 일종으로, 온라인 데이트나 소셜 미디어를 통해 가짜 프로필을 만들어 상대를 속이는 행위다. 이러한 상황에서 VPN은 사용자가 안전한 연결을 유지하고 사기 행위를 방지하는 데 도움이 된다. VPN을 통해 사용자는 상대방의 신원을 확인하고 의심스러운 활동을 감지할 수 있다. 서프샤크 VPN은 구독 요금제 가입 후 7일간의 무료 체험을 제공하고 있다. ⓒ Surfshark 그 외에도 유료 VPN만의 강점을 적극 이용해야 하는 이유는 다음 3가지로 요약할 수 있다. 보안 강화 해외 여행객이 증가함에 따라 공공 와이파이를 사용하는 경우가 늘어나고 있다. 그러나 공공 와이파이는 보안이 취약해 개인 정보를 노출할 위험이 있다. 따라서 VPN을 사용하여 데이터를 암호화하고 개인 정보를 보호하는 것이 중요하다. 서프샤크 VPN은 사용자의 개인 정보를 안전하게 유지하고 해킹을 방지하는 데 유용하다. 개인정보 보호 인터넷 사용자의 검색 기록과 콘텐츠 소비 패턴은 플랫폼에 의해 추적될 수 있다. VPN을 사용하면 사용자의 IP 주소와 로그를 숨길 수 있으며, 개인 정보를 보호할 수 있다. 또한 VPN은 사용자의 위치를 숨기고 인터넷 활동을 익명으로 유지하는 데 도움이 된다. 지역 제한 해제 해외 여행 중에도 한국에서 송금이 필요한 경우가 생길 수 있다. 그러나 IP가 해외 주소이므로 은행 앱에 접근하는 것이 제한될 수 있다. VPN을 사용하면 지역 제한을 해제해 해외에서도 한국 인터넷 서비스를 이용할 수 있다. 따라서 해외에서도 안전하고 편리하게 인터넷을 이용할 수 있다. 빠르고 안전한 유료 VPN, 서프샤크 VPN ⓒ Surfshark 뛰어난 보안 서프샤크 VPN은 강력한 암호화 기술을 사용하여 사용자의 인터넷 연결을 안전하게 보호한다. 이는 사용자의 개인 정보와 데이터를 보호하고 외부 공격으로부터 사용자를 보호하는 데 도움이 된다. 다양한 서버 위치 서프샤크 VPN은 전 세계 곳곳에 여러 서버가 위치하고 있어, 사용자가 지역 제한된 콘텐츠에 액세스할 수 있다. 해외에서도 로컬 콘텐츠에 손쉽게 접근할 수 있음은 물론이다. 속도와 대역폭 서프샤크 VPN은 빠른 속도와 무제한 대역폭을 제공하여 사용자가 원활한 인터넷 경험을 누릴 수 있도록 지원한다. 온라인 게임, 스트리밍, 다운로드 등 대역폭이 필요한 활동에 이상적이다. 다양한 플랫폼 지원 서프샤크 VPN은 다양한 플랫폼 및 디바이스에서 사용할 수 있다. 윈도우, 맥OS, iOS, 안드로이드 등 다양한 운영체제 및 디바이스에서 호환되어 사용자가 어디서나 안전한 인터넷을 즐길 수 있다. 디바이스 무제한 연결 서프샤크 VPN은 무제한 연결을 제공하여 사용자가 필요할 때 언제든지 디바이스의 갯수에 상관없이 VPN을 사용할 수 있다.



