
디지털 트랜스포메이션은 모든 기업이 원하는 목표다. 그렇다면 디지털 트랜스포메이션을 통해 이루고자 하는 것은 무엇일까? 기업이 원하는 것은 ‘업무의 변화’다. 주변을 둘러보면 데이터와 인공지능으로 업무의 변화를 끌어내는 기업을 어렵지 않게 찾을 수 있다. 정말 데이터와 인공지능은 모든 기업에게 열린 기회일까? 물론이다. 의지만 있다면 누구에게나 열려 있는 기회다. 이와 관련해 ‘IBM 클라우드 이노베이션 심포지엄(IBM Cloud Innovation Symposium)’에서 AI 전체 라이프사이클을 지원하는 데이터 및 AI 플랫폼 활용 방안이 발표돼 흥미롭다.
잘 준비된 조직과 그렇지 않은 곳의 차이
인공지능을 새로운 경쟁력의 원천으로 삼을 수 있는 기업에는 한 가지 공통점이 있다. 인공지능으로 데이터라는 자산에 새로운 가치를 불어넣기에 성공한 기업은 모든 이해 관계자가 원활히 협업할 수 있는 환경을 잘 갖추고 있다. 데이터 엔지니어, 데이터 과학자, 비즈니스 분석가, 앱 개발자, 현업 사용자 모두가 협업할 수 있는 플랫폼을 보유한 것이다. 이런 환경을 갖추기는 사실 쉽지 않다. 데이터 수집 단계부터 넘어야 할 산이 많다. 수집해야 할 대상이 너무 많다는 문제가 다음 표에서 잘 나타난다.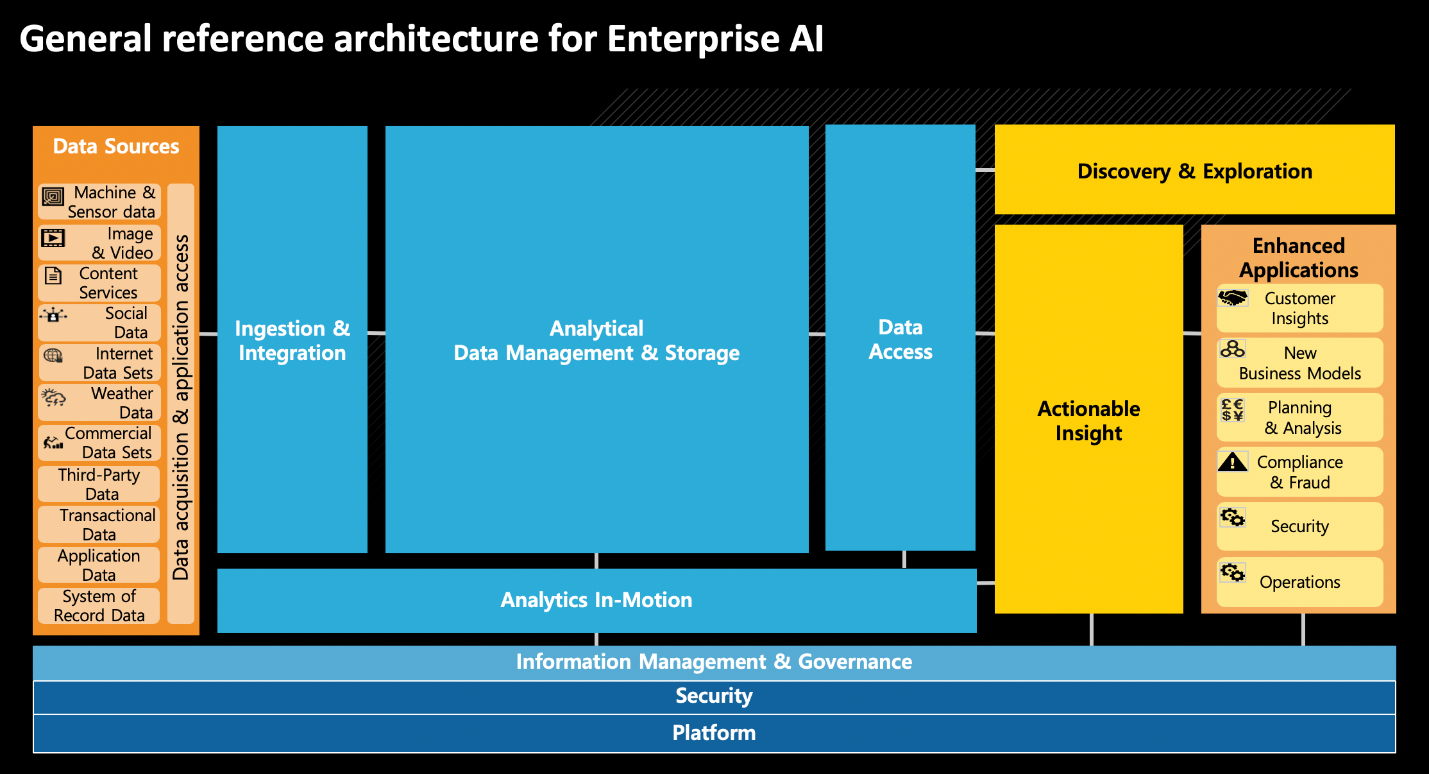
또한, 인공지능을 위해 사용하는 데이터의 위치도 사내 시스템, 클라우드, 엣지 컴퓨터 등 다양한 곳에 있다. 데이터에 쉽고, 빠르게 접근할 수 있는 데이터 파이프라인을 설계하는 것은 시작일 뿐이다. 첨단 분석과 모델 개발, 배포, 인퍼런싱 과정까지 일련의 흐름을 유지하면 단일 플랫폼에서 진행되게 하려면 기술적으로 살펴야 할 것이 많다. 이런 이유로 보통 데이터 파이프라인과 인공지능 관련 머신러닝 워크플로우를 별개로 생각하고 접근하게 된다. 라이프사이클 측면에서 하나의 플랫폼으로 수용하는 것이 이상적이란 것을 알지만, 기술적 구현의 어려움으로 따로따로 접근하는 결정을 내리게 되는 것이다. 이것이 바로 IBM이 IBM Cloud Pak for Data를 만든 이유다.
전체 인공지능 라이프사이클을 지원하는 플랫폼
IBM Cloud Pak for Data는 여러 곳에 분산된 데이터 원천에 쉽고 빠른 접근을 보장한다. 또한, 데이터 엔지니어가, 데이터 과학자, 개발자, 비즈니스 현업 부서 사용자 등을 위한 데이터 파이프라인을 간편하게 만들 수 있는 환경을 제공한다. 분석가와 개발자는 자신의 원하는 첨단 분석을 수행하고, 각종 앱과 서비스에 머신러닝 모델을 개발하고 배포할 수 있다. 이 모든 작업이 하나의 플랫폼에서 개방형 표준 기술에 기초해 이루어진다.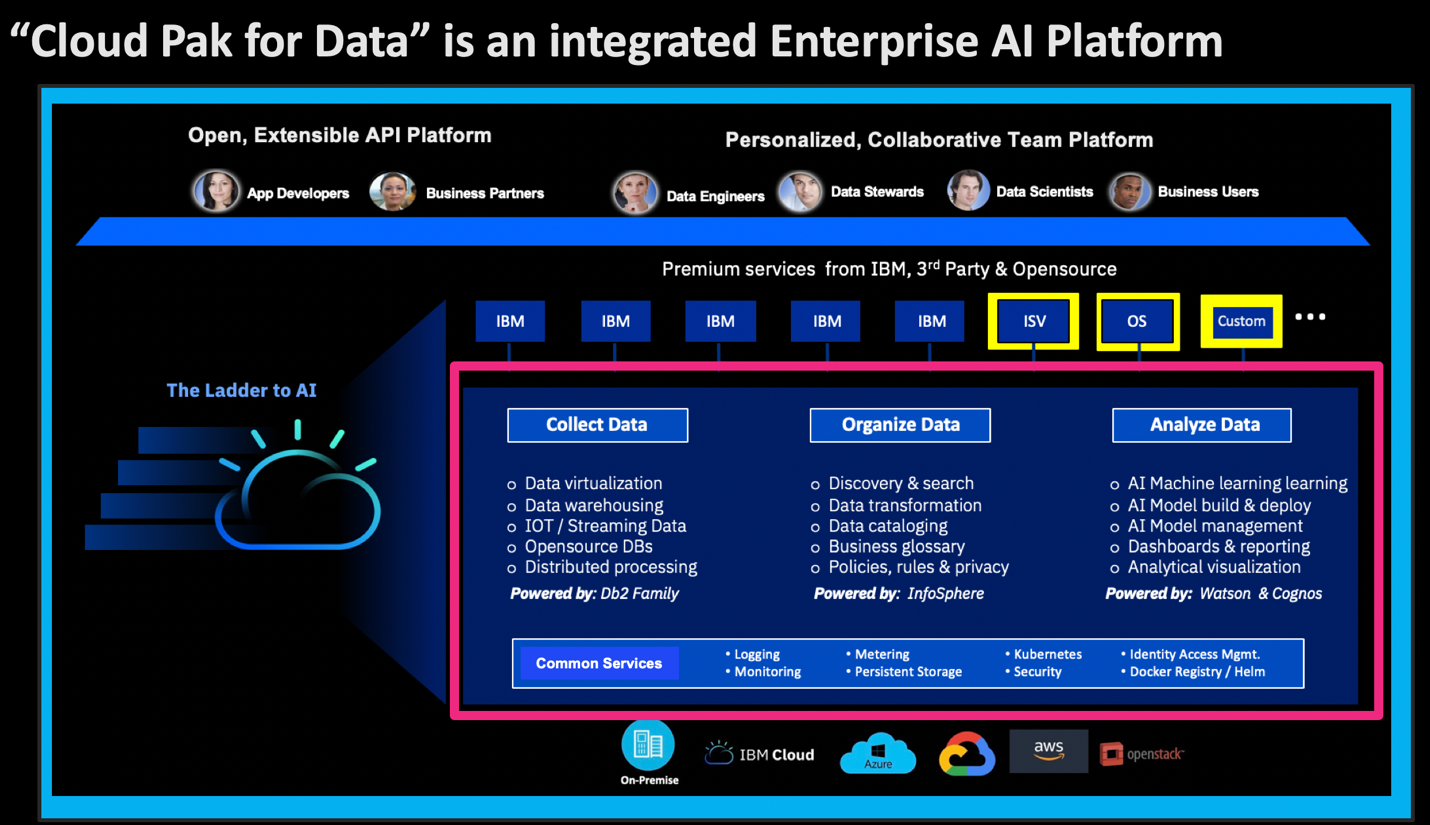
단일 정보 아키텍처 기반을 토대로 전체 인공지능 라이프사이클을 지원하는 IBM Cloud Pak for Data가 기업의 업무에 어떤 영향을 주었는지, 독일의 한 은행의 신용 위험 관리 예시를 통해 알아보자. 신용 평가와 위험 관리 측면에서 이 은행의 이해관계자는 어떻게 원활하게 협업하고 있을까? 시스템 관리자, 데이터 엔지니어, 데이터 과학자, 위험 분석가 각각의 관점에서 IBM Cloud Pak for Data가 어떻게 업무 처리 방식의 변화를 이끄는지 살펴보자.

먼저 각자의 미션을 살펴보자. 위험 평가에 인공지능을 적용할 때 시스템 관리자에게 주어진 숙제는 여러 클라우드에 분산된 데이터를 수집하는 것이었다. 데이터 엔지니어가 좀 더 쉽게 원하는 데이터에 접근할 수 있도록 돕는 것이 이들에게 주어진 임무다. 다음으로 데이터 엔지니어가 해야 할 일은 데이터 과학자를 위해 데이터를 어떤 플랫폼에 담아 놓을지 결정하고, 여기에 맞춰 원천 데이터를 신속하게 전처리를 하는 것이었다.
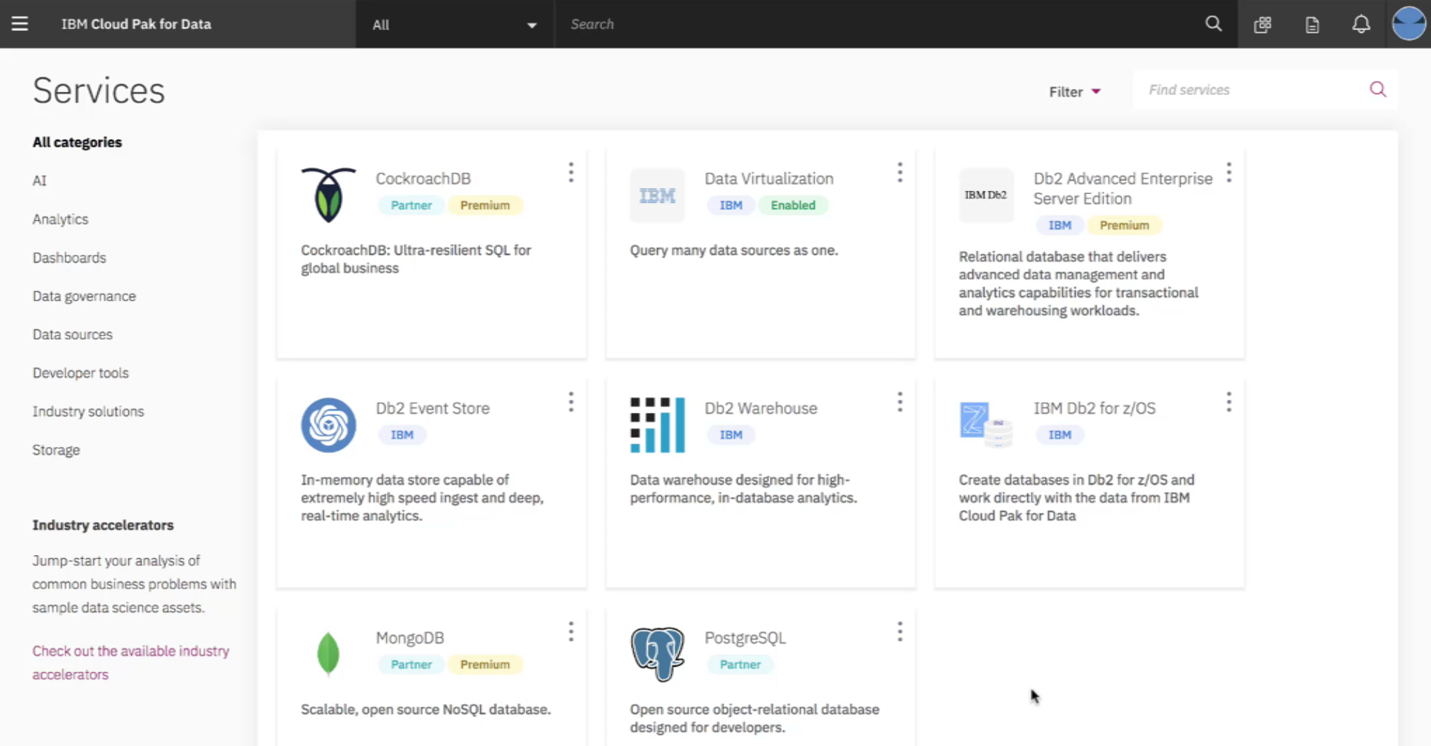
데이터 과학자에게는 시스템 관리자와 데이터 엔지니어가 열심히 준비해준 데이터 세트를 이용해 데이터 세트 카탈로그를 만들고, 인공지능 모델을 개발하고, 최적화하는 작업을 할당했다.
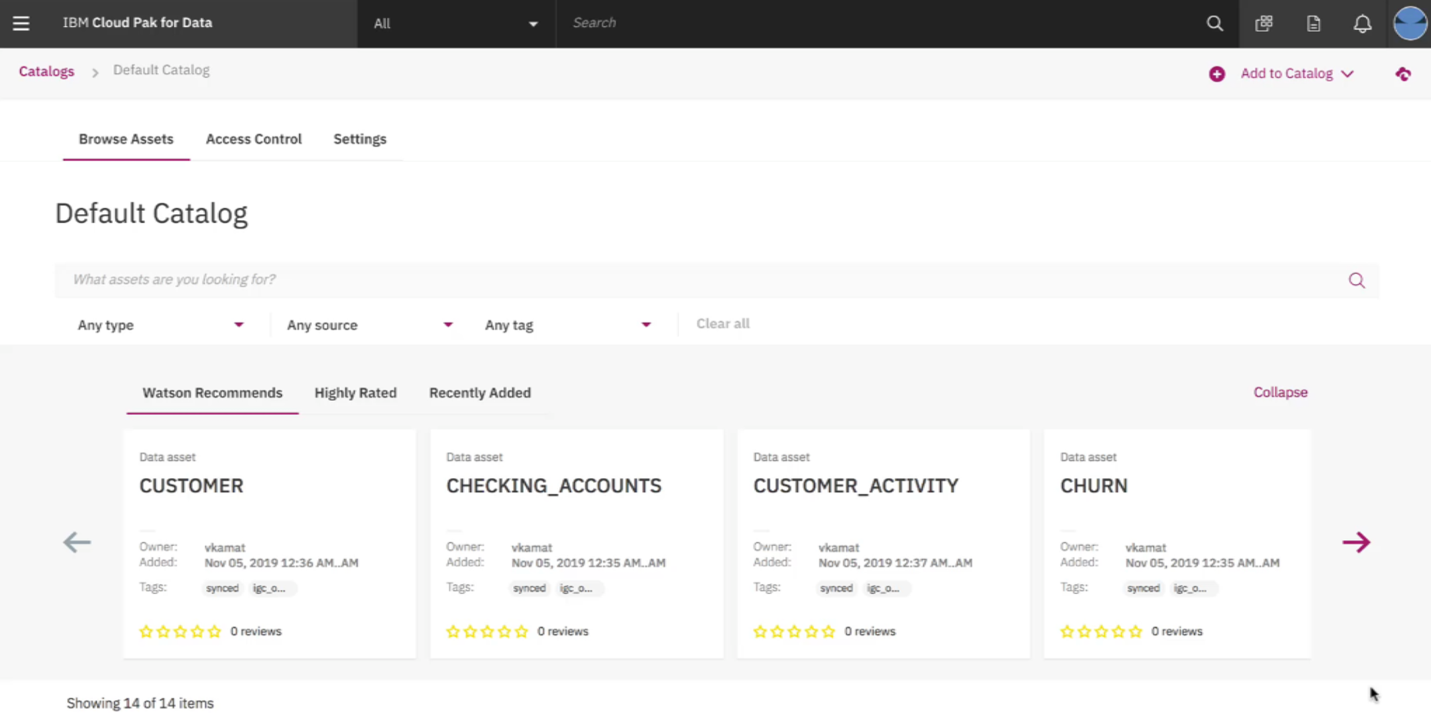
위험 분석가는 대출 관련 애플리케이션 분석을 담당했다. 여기에는 편향에 대한 분석도 포함된다. 가령 위험 평가 모델이 안전하다고 판단했는데 나중에 이 고객의 신용에 문제가 생겼을 때, 인공지능이 왜 그런 판단을 했는지를 알아내기 위한 분석을 하는 것이 맡은 일이었다.
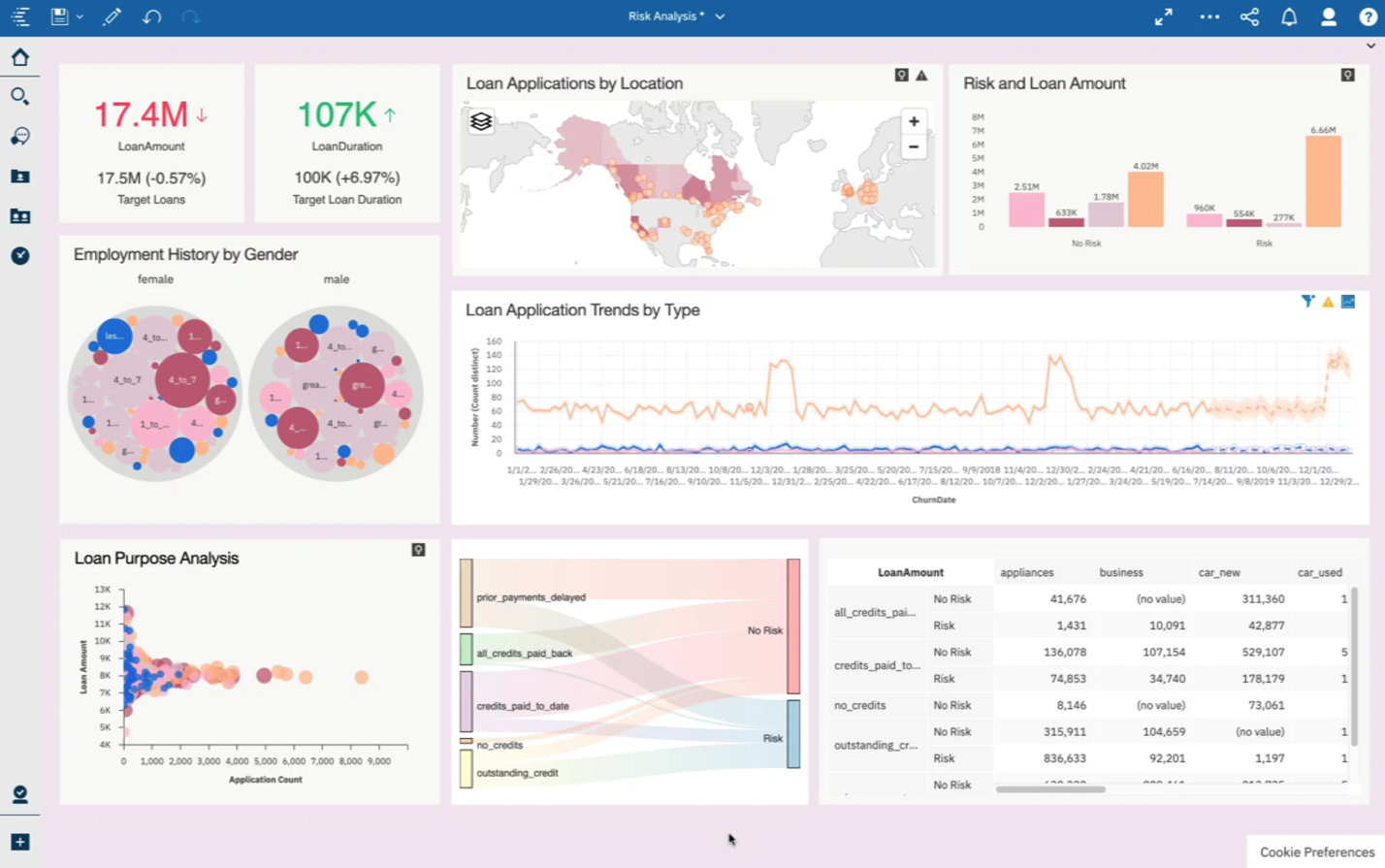
이 사례에서 IBM Cloud Pak for Data는 시스템 관리자, 데이터 엔지니어, 데이터 과학자, 위험 분석가 모두가 하나의 플랫폼에서 긴밀히 협력할 수 있는 환경을 제공했다. 각자가 사용하는 기능과 기술은 다르지만, 원하는 것을 자신의 임무에 맞게 IBM Cloud Pak for Data 환경에서 선택해 사용할 수 있다. 마치 스마트폰에서 앱을 선택해 쓰는 것처럼, IBM Cloud Pak for Data에서 필요한 기능이나 도구를 골라 사용하는 것이다. 사례로 든 독일 은행의 경우 각각의 사용자는 셀프서비스 방식으로 자신이 맡은 일을 처리했다.

지속적인 인공지능 도입 노력이라는 여정에서 IBM Cloud Pak for Data는 기업과 함께, 매끄럽게 연결되는 가치 사슬을 생성하고 모든 이해관계자가 하나의 플랫폼에서 협업할 수 있도록 지원하는 역할을 수행한다.



